
Este es el primero de una serie de artículos en que se experimenta con modelos de machine learning y los índices de percepciones de consumidores y empresarios. El objetivo del experimento es analizar cómo los índices de percepciones pueden ayudar a predecir variables económicas, e introducir el uso de modelos de machine learning al análisis económico.
El código utilizado en este artículo se puede encontrar en GiHub. También se puede visualizar en Jupyter NBViewer.
Contenidos
Contenidos
¿Qué variable predecir? IMACEC
La variable dependiente es el IMACEC, en particular, la tasa de crecimiento anual del IMACEC. Esta variable fue seleccionada debido a que se trata de un indicador muy importante para la economía chilena; debido a que tiene frecuencia mensual, al igual que los índices de confianza; y gracias a que se cuenta con predicciones de terceros para comparar (encuesta de percepciones económicas).
Se usa la tasa de crecimiento en doce meses del IMACEC debido a que refleja mejor el ciclo económico y se encuentra limpia de variaciones estacionales. Además, se correlaciona mejor con los índices de confianza.
Como ejemplo, se muestra la serie del IMACEC junto con la del IPECO, desde el año 2005 en adelante (ambas series fueron estandarizadas, para mostrarlas en la misma escala):
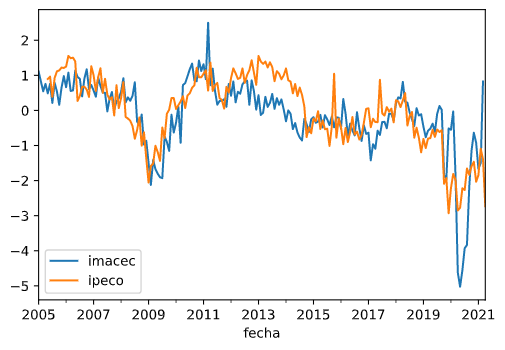
En adelante, cuando me refiera a IMACEC me estaré refiriendo a la tasa de crecimiento anual del IMACEC.
Correlación entre el IMACEC y los índices de confianza
A continuación, se muestra la matriz de correlaciones entre la tasa de crecimiento anual de IMACEC y los índices de confianza de consumidores (IPECO, IPEC) y empresarios (ICE, IMCE).
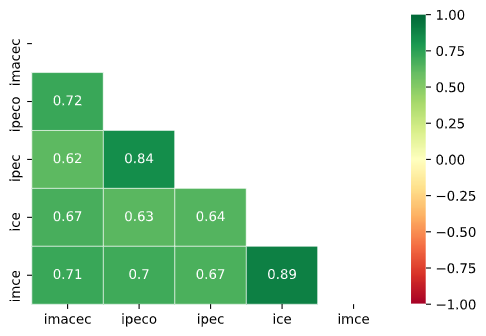
En la primera columna se observa la correlación de los índices de confianza con el IMACEC. Se observa que la variable más correlacionada es el IPECO (0.72), seguida del IMCE (0.71). También se observa una alta correlación entre los dos índices de confianza de consumidores (IPECO, IPEC; 0.84) y los dos índices de confianza empresarial (ICE, IMCE; 0.89).
Variables predictoras: índices de confianza
Las variables predictoras serán los índices de confianza IPECO, IPEC, ICE e IMCE, y los índices de percepciones relacionados con cada variable; que en el caso de los índices de consumidores corresponden a los índices por pregunta; y en el caso de los índices de empresarios corresponden a los índices por sector económico. Los índices de confianza son un promedio de los índices de percepciones.
Además, se realizarán predicciones usando todos los índices de consumidores disponibles, todos los índices de empresarios disponibles, y todos los índices de percepciones. Es decir, las distintas combinaciones de índices serán las siguientes:
- IPECO
- IPEC
- ICE
- IMCE
- Confianza de los consumidores (IPECO + IPEC)
- Confianza empresarial (ICE + IMCE)
- Todos los índices
Es importante mencionar que los índices iniciaron sus mediciones en distintas fechas, por lo que algunas series son más largas que otras. Además, algunos índices tenían una frecuencia mensual en sus inicios, que luego se convirtió en frecuencia mensual. Por otro lado, los índices de confianza están conformados por una cantidad variable de índices de percepciones. Por lo tanto, las bases de datos a utilizar tendrán dimensiones distintas dependiendo de cada índice.
Luego de eliminar las filas con missing values se obtuvieron bases de datos con las siguientes dimensiones:
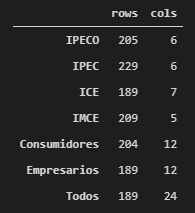
La serie más larga es la del IPEC y la más corta es la del ICE. En el caso de las bases de datos que incluyen a todos los índices de consumidores, empresarios, y todos los índices en general, el tamaño de dichos datos está acotado al tamaño de la intersección de los índices que contiene. En otras palabras, el número de filas es tal que se encuentren valores para todos los índices de confianza y percepciones.
Train y Test sets
El train set corresponde al conjunto de datos usado para entrenar (ajustar) los modelos. Se utilizarán todos los datos disponibles excepto por la última observación (último mes, más reciente), que corresponde al valor del IMACEC desconocido, que será utilizado como test set.
Por ejemplo, durante los primeros días de mayo de 2021 se publicó el IMACEC de marzo de 2021. El IMACEC de abril no se conocerá hasta junio. Simultáneamente, durante los primeros días de mayo se publicaron los índices de confianza de abril de 2021. Por lo tanto, en mayo de 2021, la última fila de datos contiene los datos de abril de 2021, es decir, los datos de percepciones y el IMACEC desconocido (missing value). Con estos datos se puede hacer una predicción del IMACEC de abril de 2021.
Modelo: XGBoost
El modelo utilizado es XGBoost, una implementación de Gradient Boosting Decision Tree (GBDT). Se trata de un modelo de ensemble learning en que se utilizan árboles de decisión para hacer predicciones de la variable dependiente. El modelo es secuencial: un primer árbol se ajusta a la variable dependiente—minimizando el error cuadrático medio—hace predicciones y se calculan los errores de predicción. Luego, los errores del primer modelo se transforman en una nueva variable dependiente, un segundo árbol se ajusta a dicha variable, se hace una predicción y se calculan los errores de predicción. Así, el proceso continúa, iterativamente. En otras palabras, cada nuevo modelo en la secuencia se enfoca en corregir los errores cometidos por el modelo anterior.
Parámetros del modelo
El modelo depende de ciertos parámetros, que se pueden calibrar para obtener una mejor predicción. En este experimento se calibraron los siguientes parámetros:
- Colsample_bytree. Número de variables a considerar en cada modelo, que son seleccionadas aleatoriamente.
- N_estimators. Número total de modelos en la secuencia.
- Max_depth. Profundidad máxima de cada árbol.
- Eta. Tasa de aprendizaje (learning rate). Porcentaje en que las predicciones de cada nuevo modelo son tomadas en cuenta para la predicción acumulada.
- Min_child_weight. Número mínimo de observaciones en el nodo final de cada árbol.
Los parámetros se calibran para evitar el sobreajuste del modelo, es decir, para evitar que el ajuste sea tan bueno que empieza a predecir la parte aleatoria de los datos, que es particular del train set y, por lo tanto, hace que el modelo sea no generalizable. En otras palabras, los parámetros son variables que permiten regularizar las predicciones, permitiendo que el modelo realice mejores predicciones fuera de la muestra.
Cómo se calibran los parámetros del modelo
Para calibrar los modelos se usó k-fold cross validation, con k=4. Además, se usó una grilla de parámetros, con distintos valores para los parámetros descritos anteriormente. Esto quiere decir que, para cada combinación de parámetros, se ajustó un modelo determinado 4 veces, usando un 75% de los datos para ajustar el modelo, y un 25% para validarlo, es decir, para calcular una medida de error (RMSE). Así se calcula un CV-RMSE, promediando los 4 errores calculados para cada ajuste. El proceso se repite para todas las combinaciones de parámetros y se selecciona el modelo con menor CV-RMSE.
Las grillas usadas fueron las siguientes:
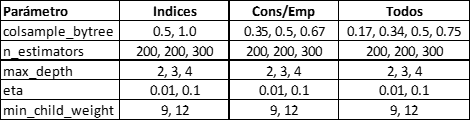
La principal diferencia se da en colsample_bytree, en que el número indica el porcentaje de variables a utilizar. En el caso de los índices individuales (Índices), se consideró usar el 50% o 100% de las 5 a 7 variables. En el caso de los grupos de índices de consumidores o empresarios (Cons/Emp) se consideró usar el 35%, 50% o 67% de las 12 variables. En el caso del modelo con todos los índices se consideró usar el 17%, 34%, 50% o 75% de las 24 variables.
Resultado de la calibración
El resultado del proceso de calibración de los modelos fue el siguiente:
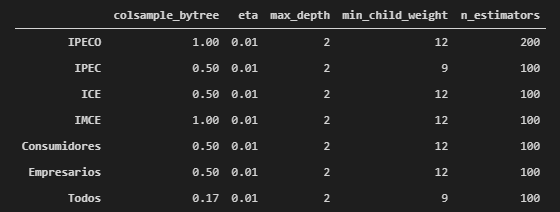
Los resultados en términos de CV-RMSE, y medidas de error dentro de la muestra son los siguientes:
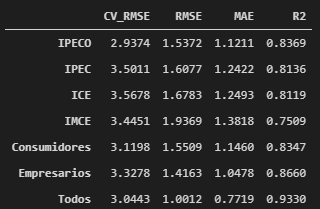
Se observa que el modelo en base al IPECO fue el que obtuvo el menor CV-RMSE, mientras que para las medidas dentro de la muestra (train set) el mejor modelo fue el que incluyó todos los índices. En el siguiente cuadro se observa el ratio entre CV-RMSE y RMSE, que se puede interpretar como una medida de sobreajuste. Se observa que el sobreajuste es menor para el modelo en base al IMCE y mayor para el modelo en base a todos los índices.

Ajuste a la muestra completa
Una vez seleccionados los parámetros que producen el menor CV-RMSE, el siguiente paso es ajustar cada modelo al train set completo, usando los mejores parámetros seleccionados. A continuación, se hace una predicción para el IMACEC.
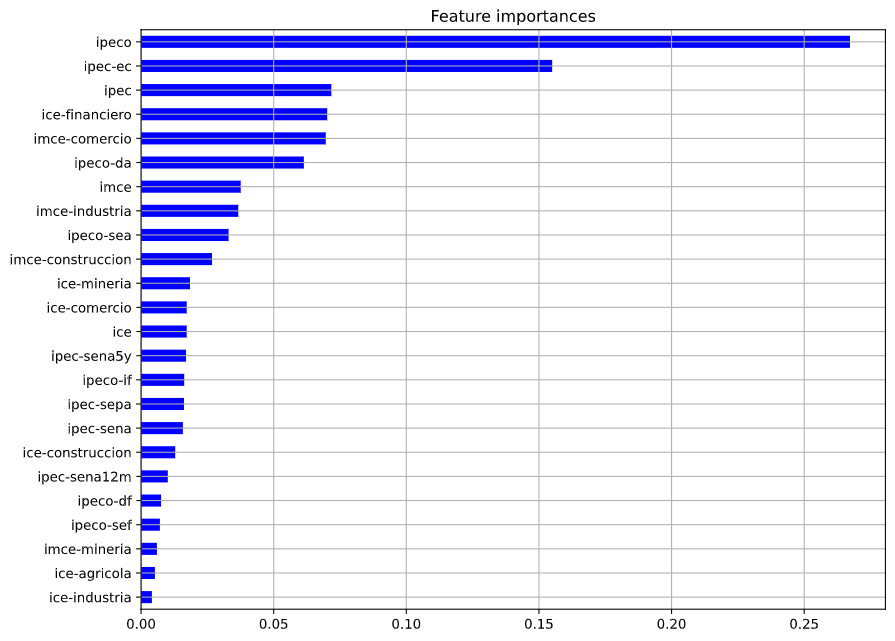
Antes de pasar a las predicciones se muestra el gráfico de feature importances, que es un gráfico que muestra, para cada modelo, cómo aumentaría el MSE si se omite alguna de sus variables. Se muestran los resultados para el caso de los modelos de consumidores, empresarios y todos los índices. El resto de los gráficos se puede ver en la notebook. Se debe mencionar que estos gráficos son válidos sólo para el modelo respectivo, sus resultados no se pueden generalizar y, de hecho, pueden cambiar bastante si se cambian los parámetros del modelo, o si cambia la muestra utilizada.
En el caso del modelo en base a índices de confianza de los consumidores, la variable más importante fue el IPECO, seguido del IPEC y la percepción del desempleo actual del IPECO.
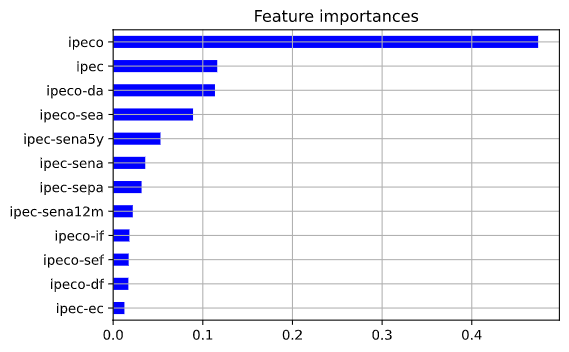
En el caso del modelo en base a índices de confianza empresarial, la variable más importante fue el IMCE, seguida del índice de la construcción del IMCE, y el índice del sector financiero del ICE.
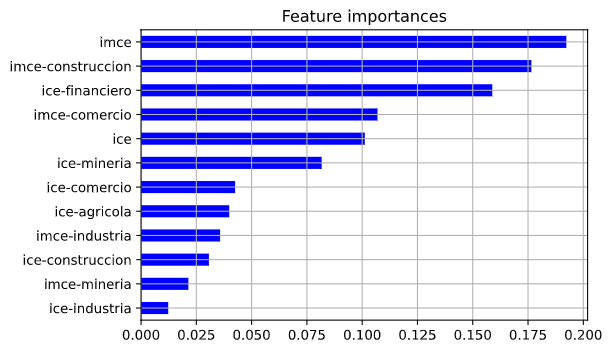
Al usar todas los índices, la variable más importante fue el IPECO, seguido de la expectativa de consumo de artículos para el hogar del IPEC, y el IPEC.
Predicción del IMACEC
En el siguiente cuadro, en la columna Imacec, se muestra la predicción de los modelos en base a cada grupo de índices. La última fila muestra la predicción de la encuesta de expectativas económicas, que es la mediana de las predicciones entregadas por los encuestados. La columna diferencia muestra la resta abs(Predicción Encuesta – Predicción Modelos).
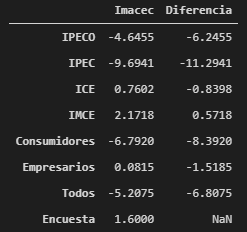
Se observa una gran heterogeneidad en las predicciones. La mayor predicción la da el modelo en base al IMCE (2,17%), mientras que la menor predicción la da el modelo en base al IPEC (-9,69%). La mayor diferencia con la predicción de la encuesta de expectativas económicas la tiene el modelo en base al IPEC (-11,29), y la menor diferencia se encuentra con el modelo en base al IMCE (0.57).
¿Cómo se explican las diferencias?
¿Por qué hay tanta diferencia entre las predicciones de los distintos índices?
En general se observa que las predicciones en base a índices de consumidores son mucho más bajas que las predicciones realizadas en base a índices empresariales. En el caso del modelo que usó todos los índices su predicción es baja porque predomina el efecto de los índices de consumidores, que resultaron más importantes que los índices empresariales en dicho modelo.
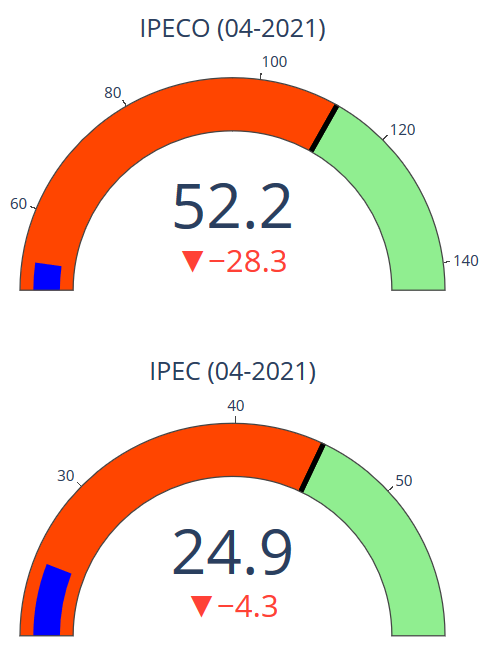
Las diferencias se explican principalmente por el nivel que mostraban los índices en abril de 2021, que se puede observar en los siguientes gráficos, en que los valores mínimos y máximos corresponden a los mínimos y máximos históricos, y el umbral corresponde a la mediana histórica. Sobre el umbral se puede considerar que la confianza es optimista, y por debajo se considera pesimista.
Se observa que la confianza de los consumidores se encuentra en un nivel muy bajo, muy pesimista, evaluando su nivel desde una perspectiva histórica.
En cambio, la confianza empresarial, si bien es pesimista, se encuentra sólo un poco por debajo del nivel neutral. Es decir, se podría decir que la confianza empresarial estaba levemente pesimista.
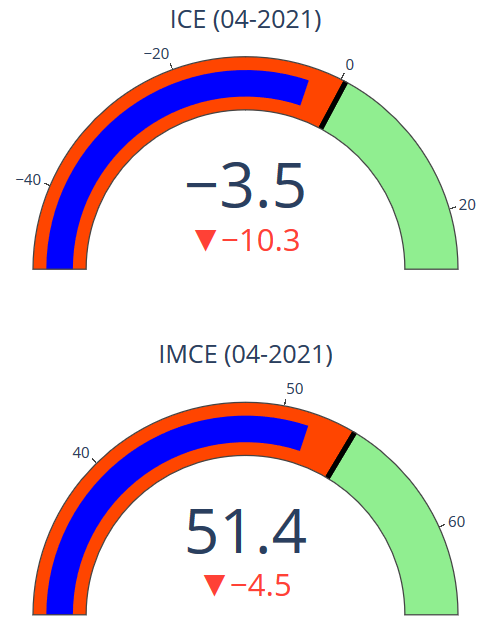
En consecuencia, las predicciones de los modelos en base a la confianza de los consumidores son más pesimistas (más negativas) que las predicciones de los modelos en base a la confianza empresarial.
Por otro lado, se podría pensar que los empresarios tienen más y mejor información acerca de la dinámica de la actividad económica que los consumidores, y que, por lo tanto, sus predicciones deberían ser más precisas, como lo sugiere la menor diferencia encontrada con la predicción de la encuesta de expectativas económicas. Si es así se podría esperar que estas predicciones sean las mejores, aunque los análisis anteriores sugieren que la confianza de los consumidores sería un mejor predictor del IMACEC en promedio.
¿Por qué hay tanta diferencia con la predicción de la encuesta de expectativas económicas?
Las predicciones de la encuesta de expectativas económicas son realizadas por economistas profesionales, que utilizan una gran cantidad de variables en sus modelos, no sólo variables de percepciones. Si los modelos de machine learning presentados en este artículo incluyeran otras variables, además de las percepciones económicas, probablemente tendrían un mejor desempeño.
Por otro lado, las variables de percepciones son medidas a través de encuestas de tamaño relativamente reducido, por lo que se trata de estimaciones de la confianza, cuyo error de estimación puede ser significativo. Esto se observa en las grandes variaciones que experimentan estos índices entre un mes y otro. Una forma de contrarrestar esta falta de precisión es usar promedios móviles de las variables, por ejemplo, un promedio móvil trimestral, que suavice los cambios.
Por último, se menciona que la correlación entre los índices de confianza y otras variables económicas puede variar en el tiempo. Por ejemplo, en un artículo anterior se observó que la correlación entre confianza de los consumidores y crecimiento del consumo agregado depende del nivel del crecimiento del consumo, y que sería mayor cuando el crecimiento del consumo es alto. ¿Podría suceder algo similar con la correlación entre confianza e IMACEC?
Evaluación de las predicciones
Para evaluar los distintos modelos se comparará la predicción realizada con el dato real del IMACEC de abril de 2021, que será publicado en junio de 2021.
¿Qué significarán los resultados?
Que un modelo se desempeñe mejor que otros en una predicción puntual, no implica necesariamente que sea el mejor, o que las variables en las que se basa sean las mejores. Simplemente, se trata del mejor modelo en dicha predicción puntual. Para hacer una mejor evaluación, este proceso se debe repetir en múltiples oportunidades, y luego obtener un promedio. De esta manera se pueden obtener medidas como el RMSE (raíz del error cuadrático medio) o el MAE (error absoluto medio). Si se quiere ser aun más riguroso se debería usar un test estadístico, para determinar si las diferencias entre las predicciones de distintos modelos son estadísticamente significativas o no.
Sin embargo, este torneo experimental no tiene la intención de ser extremadamente riguroso, sino simplemente generar interés y discusión en torno al tema. En consecuencia, se dispondrán las siguientes reglas.
Reglas del torneo experimental
Los modelos se evaluarán en una dinámica similar a la de un Torneo Experimental.
- Será un Torneo ya que los distintos modelos irán compitiendo por lograr el mejor desempeño.
- Será Experimental ya que se irán introduciendo cambios en la modelación que hagan más interesante el torneo, y que permitan ir mejorando la precisión de las predicciones.
Reglas:
- Cada modelo se ajustará usando la mayor cantidad de datos disponibles a la fecha. Eso significa que para la predicción del mes N, se volverán a calibrar y ajustar los modelos para considerar la información disponible hasta el mes N-1.
- Para no complicar demasiado la calibración de los modelos, se usará la misma grilla de parámetros para calibrar los modelos basados en índices individuales (IPECO, IPEC, ICE, IMCE), otra para los grupos de índices (consumidores y empresarios) y otra para el modelo en base a todos los índices.
- Se permitirá hacer feature engineering, es decir, crear nuevas variables a partir de las variables existentes. Las nuevas variables que se creen deberán estar disponibles para todos los modelos. Por ejemplo: promedios móviles, agregaciones de índices, encodings, interacciones, etc.
- La fecha se podrá considerar como una variable adicional de cada conjunto de datos.
- En cada nuevo mes se creará una nueva notebook, y tanto la nueva como la antigua se guardarán en GitHub, por si se desea consultar retrospectivamente más adelante.
- La predicción de la encuesta de expectativas económicas no compite, pero se usará como referencia.
- Dado que los errores de predicción a obtener en los sucesivos meses no serán comparables, se elaborará un ranking mensual en base al error absoluto de predicción de los modelos. Luego, se elaborarán otros dos rankings con medidas de desempeño acumuladas: (1) uno que mida el ranking mensual promedio y (2) otro que mida el número de victorias acumuladas a la fecha.
- En cada mes se evaluará el desempeño de los modelos obtenido en el mes anterior y se realizará una nueva predicción.