
En este artículo se presenta una propuesta de Índice de Sentimiento Corporativo, un trabajo en progreso, cuyo objetivo es interpretar información financiera. En específico, el ISC es un índice de confianza empresarial que analiza e interpreta la información implícita en las cartas a los accionistas, que anualmente publican las empresas en sus memorias corporativas.
Estudios relacionados
Contenidos
Este trabajo se enmarca en la línea de la literatura económica iniciada por Baker, Bloom y Davis (2016), quienes elaboraron un índice de incertidumbre político-económica a partir de las noticias publicadas en los 10 mayores periódicos de EEUU. El índice refleja la frecuencia con que se encuentra un conjunto de palabras que señalan incertidumbre. En concreto, los artículos deben contener los siguientes tríos de palabras: “economic” o “economy”, “uncertain” o “uncertainty”, y uno o más entre “congress”, “deficit”, “Federal Reserve”, “legislation”, “regulation” o “White House”. Los autores demuestran en su investigación que el índice es capaz de predecir—a nivel de firmas—la volatilidad de los precios de las acciones, la inversión y el empleo en sectores económicos sensibles; y a nivel macro, la inversión agregada, actividad económica, y el empleo.
En Chile, se publica un índice similar, propuesto por Cerda, Silva y Valente (2018), investigadores de Clapes UC, quienes construyeron dos indicadores: un índice de incertidumbre económica, y un índice de incertidumbre político-económica. En particular destaca el índice de incertidumbre económica, que refleja la frecuencia de artículos de prensa que contengan las parejas de palabras: “incertidumbre” o “incierto” y “economía” o “económico”. Los artículos de prensa analizados se obtienen de El Mercurio, La Tercera y Diario Financiero. Los autores demuestran que el índice es capaz de predecir el PIB, el consumo, la inversión y el empleo.
Otros estudios similares en Chile son los de Becerra y Sagner (2020), quienes elaboraron un índice de incertidumbre económica en base a actividad de Twitter; y el de del Pilar, Peralta y Ávila (2020), quienes realizaron un análisis del sentimiento del Informe de Percepciones de Negocios del Banco Central de Chile.
Una propuesta alternativa basada en Machine Learning
En este estudio se realiza un análisis del sentimiento de las cartas a los accionistas que se publican anualmente en las memorias corporativas de las empresas del IPSA. La principal contribución de este trabajo es que, a diferencia de los otros estudios que interpretan la información implícita en los textos en base a un conjunto arbitrario de palabras, en este estudio la clasificación del sentimiento se realiza mediante algoritmos de Machine Learning, que seleccionan automáticamente las palabras que mejor reflejan los sentimientos optimistas. De esta manera, se busca que la clasificación del sentimiento económico encontrado en los textos sea lo más imparcial y completa posible, basada en patrones y combinaciones de palabras que se encuentran frecuentemente en los textos, y que pueden ser identificadas de forma eficiente y sistemática por los algoritmos.
El algoritmo se utilizó para identificar el sentimiento económico implícito en las cartas a los accionistas de las empresas del IPSA, y en base a esta clasificación se elaboró el índice de sentimiento corporativo (ISC).
Base de datos
Se construyó una base de datos de textos económicos, principalmente en base a noticias económicas publicadas en diversos medios prensa online durante abril de 2020 y abril de 2021. Las noticias fueron etiquetadas manualmente como pesimistas, neutrales y optimistas. Adicionalmente, la base de datos contiene fragmentos de cartas a los accionistas de años anteriores, en que claramente se observa una polaridad específica: pesimista, neutral u optimista. En total la base de datos cuenta con 1.346 textos (los conceptos polaridad y sentimiento se usan como sinónimos).
Los textos debían cumplir la condición de expresar claramente ideas con cierta polaridad, sin ambigüedades que pudieran confundir al algoritmo. Si, por ejemplo, un texto contenía una mezcla de ideas pesimistas y optimistas, se optaba por omitirlo, o bien se separaban los textos en fragmentos en con etiquetas individuales. Otra condición importante fue que los textos contuvieran información económica, de forma que las palabras y combinaciones de palabras encontradas coincidieran con las que pudiéramos encontrar en las cartas a los accionistas. En otras palabras, los textos debían contener la jerga mayormente utilizada en los ámbitos de la economía, negocios, finanzas, marketing, etc.

Procesamiento de los datos
Los textos son datos no estructurados, ya que no tienen una estructura común. De hecho, cada texto es distinto de otro, en distintas dimensiones, por ejemplo: las palabras utilizadas, el número de caracteres, palabras o párrafos, combinaciones de palabras con significados específicos, etc. Por lo tanto, antes de utilizar estos datos se les debe dar una estructura.
Los textos fueron pre-procesados para darles estructura. En primer lugar, se simplificaron los textos, pasando todas las letras a minúsculas, retirando los números y caracteres especiales (signos de puntuación, exclamación, interrogación, paréntesis, comillas, etc.), se quitaron los acentos y las StopWords. Las StopWords son palabras sin un significado o sentido claro—como los artículos, pronombres y preposiciones—que se usan con frecuencia en todo tipo de textos, independientemente de la polaridad, por lo que no contribuyen a diferenciar los distintos sentimientos.

Luego, los textos fueron vectorizados, lo que significa representar su contenido en una matriz. Con este objetivo se crea el vocabulario de la base de datos, que es una lista de todas las palabras presentes en el total de textos. Dichas palabras pasan a ser los nombres de las columnas de la matriz. Por otro lado, cada fila de la matriz representa un texto, y los valores de las celdas indican si cada palabra del vocabulario aparece o no en el texto correspondiente.
La vectorización puede hacerse de distintas maneras. Por ejemplo, además de las palabras individuales se pueden considerar n-gramas, que son combinaciones de palabras consecutivas. Esto es importante, ya que una palabra como desempleo podría tener una connotación negativa, pero su sentido cambia a positivo si se combina con otra palabra. Por ejemplo, desempleo disminuye. Por otro lado, los valores que indican si una palabra aparece o no en un texto también pueden variar. Se puede usar el número de veces que cada palabra aparece en un texto, la frecuencia porcentual con que cada palabra aparece, o la medida Tf-idf (term frequency – Inverse document frequency), que multiplica la frecuencia con que cada palabra aparece por el inverso de la frecuencia con que aparece en el total de textos, lo que hace que las palabras muy comunes tengan un menor peso en la matriz.

Combinaciones usadas en el estudio
En este estudio se optó por usar seis combinaciones distintas de parámetros:
- El vocabulario lo componen las 3000 palabras más frecuentes, y los valores son el número de veces que aparece cada palabra en cada texto.
- El vocabulario lo componen las 3000 palabras y pares de palabras consecutivas (n-gramas=1,2) más frecuentes, y los valores son el número de veces que aparecen en cada texto.
- El vocabulario lo componen las 3000 palabras más frecuentes, y los valores son la frecuencia porcentual con que aparece cada palabra en cada texto (número de veces que aparece la palabra dividido por el total de palabras en el texto).
- El vocabulario lo componen las 3000 palabras y pares de palabras consecutivas (n-gramas=1,2) más frecuentes, y los valores son la frecuencia porcentual con que aparecen en cada texto (número de veces que aparece el n-grama dividido por el total de n-gramas en el texto).
- El vocabulario lo componen las 3000 palabras más frecuentes, y los valores son la Tf-idf de cada palabra.
- El vocabulario lo componen las 3000 palabras y pares de palabras consecutivas (n-gramas=1,2) más frecuentes, y los valores son la Tf-idf de cada n-grama.
Variable dependiente
Por último, se procesó la variable dependiente, que es la etiqueta dada a los textos (pesimista / neutral / optimista). Se usó el número 1 para distinguir los textos optimistas, y un 0 en otro caso. Esto implica que el algoritmo se entrenó para identificar textos con sentimiento positivo. El 21% de las etiquetas de la base de datos son optimistas, mientras que el restante 79% son pesimistas o neutrales.
Modelamiento
Dado que se cuenta con seis distintos conjuntos de datos, preprocesados de formas diversas, se utiliza un Stacking de modelos de clasificación, una técnica de ensemble learning, que implica ajustar un conjunto de modelos individuales a cada base de datos, cuyas predicciones luego son combinadas por un metamodelo, que entrega la predicción final. Los modelos de ensemble learning típicamente tienen un mejor desempeño que los modelos individuales, ya que permiten combinar las predicciones generadas por los modelos individuales de forma de obtener lo mejor de cada una.
El primer paso del modelamiento fue separar la muestra en tres subconjuntos de datos, seleccionados de forma aleatoria y estratificada, de forma tal que la distribución de la variable dependiente fuera la misma en cada subset. Los subsets tienen 874, 377 y 95 textos cada uno, es decir, 65%, 28% y 7% de los datos, respectivamente. Esta separación de la muestra se hizo para cada una de las seis matrices de datos.
El subset 1 se usó para entrenar los modelos individuales, seis regresiones logísticas, una para cada matriz de datos. Luego, cada uno de los modelos generó predicciones para los subsets 2 y 3. A continuación, se entrenó el metamodelo usando el subset 2, es decir, usando las predicciones de los primeros seis modelos para el subset 2 como inputs, y usando la variable dependiente del subset 2. Finalmente, se evaluó el desempeño de los modelos en el subset 3. Esta estrategia permite reducir el sobreajuste de los modelos a los datos.

Para calibrar los modelos se usó k-fold cross validation con k=5 y una búsqueda de grilla. La validación cruzada (cross-validation) significa que cada modelo se ajusta k veces, usando un (k-1)/k% de los datos, luego se hace una predicción para la parte excluida y se calcula una medida de error. De esta manera se obtienen k medidas de error, que se promedian para obtener una estimación del error fuera de la muestra (CV-Error). La métrica de error utilizada fue la Accuracy, que es el porcentaje de datos correctamente clasificados sobre el total de datos. La búsqueda de grilla significa repetir el procedimiento para una serie de valores de parámetros exógenos, que en el caso de la regresión logística pueden ser: (1) tipo de regularización, Lasso o Ridge, y (2) el parámetro asociado a la regularización (lambda). Se probaron 20 posibilidades para el valor lambda, que junto con los dos posibles métodos de regularización significó probar 40 combinaciones para cada uno de los seis modelos individuales. De esta manera se seleccionó la combinación óptima de parámetros, que es aquella que minimiza el CV-Error.
A continuación, una vez elegidos los mejores modelos, se ajustaron a los subsets 1 completos, y se hizo la predicción para los subsets 2 y 3. Luego, se repitió la búsqueda de grilla con cross-validation para el metamodelo, de forma de seleccionar sus parámetros óptimos. El metamodelo también es una regresión logística, y se buscó en la misma grilla utilizada de los modelos individuales. Una vez elegido el mejor metamodelo, se ajustó al subset2 completo y se hizo la predicción para el subset 3.
Optimización del threshold
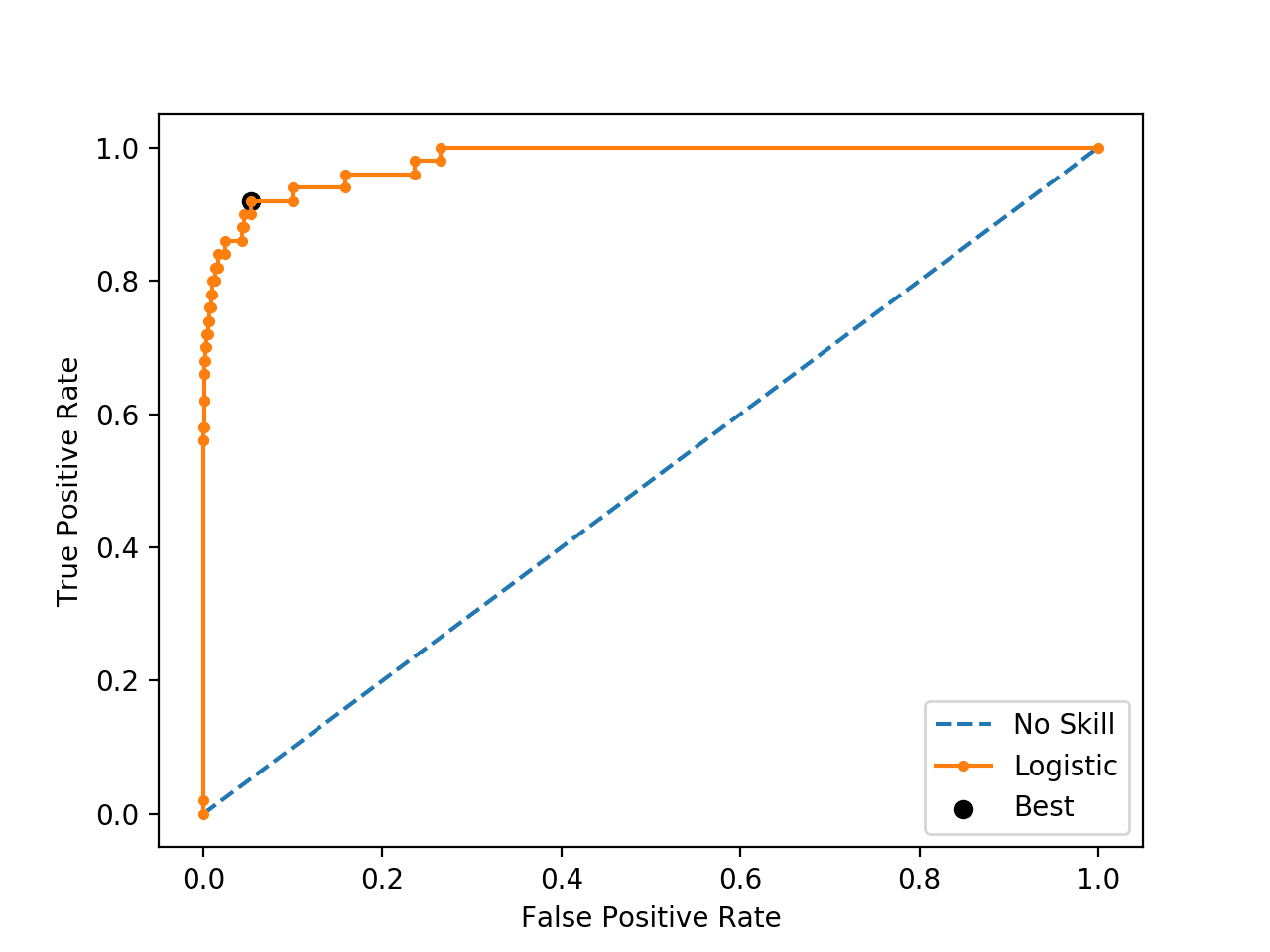
El último paso fue optimizar el threshold. El metamodelo entrega como predicción la probabilidad de que un texto sea optimista, que es un valor entre 0.0 y 1.0. Para hacer una predicción de las etiquetas [0, 1] se necesita un threshold (umbral) tal que una probabilidad mayor al threshold se considere como un 1 (etiqueta positiva). Para optimizar el threshold se hizo una búsqueda de grilla sencilla, en 200 valores equidistantes entre 0 y 1. Se optimizó usando como referencia la métrica F1, que es la media harmónica de otras dos métricas precision (porcentaje de los datos clasificados como positivos por el modelo que son efectivamente positivos) y recall (porcentaje de los datos efectivamente positivos que fueron clasificados como positivos por el modelo).
El objetivo de la calibración es elegir la combinación de parámetros exógenos (tipo de regularización, lambda, threshold) que produzca los mejores resultados de acuerdo con las métricas de error utilizadas. Una vez que ya se tienen especificados los mejores modelos, éstos se ajustan a la muestra completa, es decir, al 100% de los datos disponibles.
Próximos pasos
En el siguiente artículo de esta serie se describirán cómo se hicieron las predicciones del modelo, y se mostrarán los resultados obtenidos usando las cartas a los accionistas del año 2020.
Cabe destacar que la metodología propuesta en este artículo se puede aplicar a todo tipo de textos económicos, incluyendo el tipo de información analizado por otros índices del mismo estilo que se han publicado en el país. De hecho, esta metodología podría usarse para dar una interpretación alternativa y complementaria a dichos datos.
Pingback: Base de datos de sentimiento económico - Percepciones Económicas
Extraordinario tu trabajo, gracias por compartirlo.