
El código utilizado en este artículo se puede descargar en GitHub. También puedes visualizarlo en Jupyter Notebook.
Una forma de interpretar los índices de percepciones, como la confianza de consumidores y empresarios, es usar escalas cualitativas de confianza, que clasifican los niveles de confianza en categorías pesimistas, neutrales y optimistas. En este artículo se propone un método para construir dicha escala cualitativa, utilizando el índice de percepción de los consumidores (Ipeco, CEEN-UDD) como ejemplo. No obstante, la misma escala se puede aplicar a otros índices de percepciones.
¿Cómo se calcula el Ipeco?
Contenidos
En el Ipeco cada pregunta de la encuesta tiene una posibilidad de respuesta pesimista, neutral u optimista. A partir de las respuestas se construyen índices de percepciones, dividiendo el porcentaje de respuestas optimistas por la suma de respuestas pesimistas y optimistas. Es decir, el Ipeco es un índice de difusión, donde cada variable es una proporción, que en teoría se distribuye entre 0 y 100. Luego, los índices de percepciones se promedian para obtener el Ipeco, y los índices de coyuntura y expectativas. Finalmente, cada indicador se divide por su valor inicial y se multiplica por 100.
¿Es conveniente dividir por el valor inicial?
El Ipeco, al igual que los índices estadounidenses, Consumer Sentiment Index (Universidad de Michigan) y Consumer Confidence Index (The Conference Board) presenta sus valores como porcentaje de su valor inicial, lo que no parece muy conveniente, ya que dificulta la interpretación de los indicadores.
Antes de dividir por el valor inicial, cada indicador de la encuesta se distribuye teóricamente entre 0 y 100, lo que luego cambia. Por ejemplo, si el valor inicial es 50, el índice transformado se distribuirá entre 0 y 200; si el valor inicial es 80, el índice transformado se distribuirá entre 0 y 125. En consecuencia, tanto los niveles como las variaciones de cada indicador dejan de ser comparables.
En cambio, si no se divide por el valor inicial, todos los índices se encontrarán en la misma escala, y tanto sus niveles como sus variaciones serán comparables. Además, el valor 50 marca la base o punto de equilibrio del índice, es decir, el nivel en que hay tantas respuestas pesimistas como optimistas. Por lo tanto, los valores sobre 50 se considerarían optimistas, bajo 50 serían pesimistas, y 50 sería el nivel neutral.
A continuación, en este artículo se trabaja con el Ipeco en su escala original, de 0 a 100, para facilitar su visualización e interpretación.
¿Cómo influye la distribución de los índices en su interpretación?
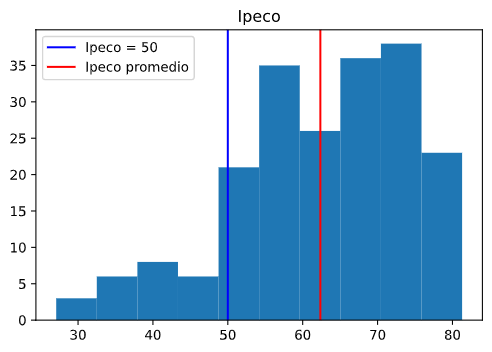
A continuación se observa el histograma de la distribución del Ipeco. Se observa que la distribución es asimétrica, y que el índice está sesgado hacia la izquierda. En líneas verticales se muestra el valor de equilibrio, 50 (línea azul), y el valor promedio del Ipeco (línea roja). Se aprecia que los consumidores son principalmente optimistas, ya que la mayor parte de las observaciones, un 87%, es mayor que 50.
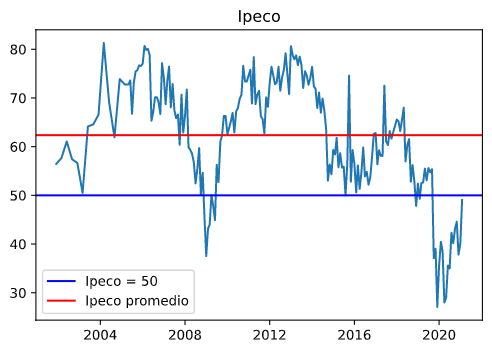
En el siguiente gráfico se muestra la serie de tiempo, donde se observa que sólo en situaciones muy excepcionales se registraron niveles pesimistas de confianza. Durante el resto de la historia, la confianza ha sido mayormente optimista.
Escala cualitativa relativa
Las observaciones anteriores sugieren que parece adecuado usar una escala relativa de confianza, en que los niveles pesimistas y optimistas sean caracterizados según algún valor de referencia que defina la escala. Por ejemplo, los niveles de confianza bajo el promedio podrían ser clasificados como pesimistas, y sobre el promedio serían optimistas. La ventaja de este método es que permite tomar en cuenta el sesgo de los consumidores hacia el optimismo, lo que en el Ipeco se debería a que mide una mayor cantidad de percepciones del futuro que del presente, y las evaluaciones del futuro suelen ser más optimistas (Bovi 2009). Sin embargo, este método también tiene desventajas: (1) la media no es buena medida de tendencia central en distribuciones asimétricas, (2) la escala cambia en el tiempo, aunque se espera que converja y se estabilice, (3) es más fácil de aplicar en índices con mayor cantidad de datos que en índices nuevos, con pocos datos (debido a la mayor varianza en el cálculo del promedio de los índices con pocos datos).
En el siguiente cuadro se muestra la media y mediana de los índices de percepciones: situación económica actual (sea), desempleo actual (da), situación económica futura (sef), desempleo futuro (df), e ingresos futuros (iif); y los índices compuestos: Ipeco (sea + da + def + df + iif), índice de coyuntura (sea + da), índice de expectativas (sef + df + iif). Se observa que las diferencias entre media y mediana son pequeñas. También se verifica que el nivel promedio de optimismo es mayor en las percepciones del futuro.
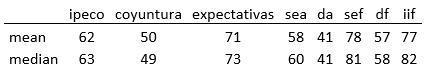
En el siguiente cuadro se muestran los valores mínimos y máximos de cada variable. Se observa que, pese a que los valores mínimos y máximos teóricos son 0 y 100, en la práctica cada variable se distribuye en un rango distinto, lo que también dificulta la comparación e interpretación de sus niveles, ya que, por ejemplo, en el caso de la percepción de la situación económica futura el valor 37 es el valor más pesimista registrado en la historia, cuya magnitud es similar al valor promedio registrado para la percepción del desempleo actual, 41 (que sería un valor neutral según la regla del promedio). Esta observación da otra justificación para el uso de escalas relativas de confianza, en la que la categorización de cada variable dependa de parámetros de su propia distribución.

Propuesta de escala cualitativa de confianza
La propuesta que se hace es la siguiente: dividir la distribución de cada índice en 5 categorías: muy pesimista, pesimista, neutral, optimista y muy optimista, usando los percentiles 20, 40, 60 y 80 de la distribución de cada variable. En otras palabras, se definen quintiles de optimismo, en que cada quintil tiene una cantidad igual o similar de observaciones.
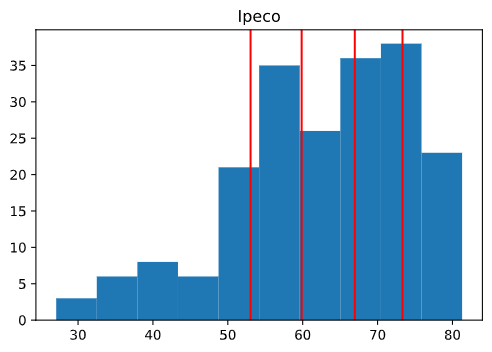
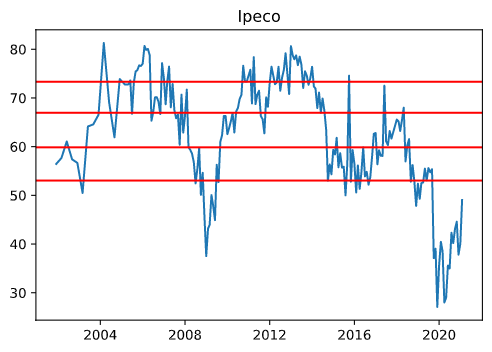
En el caso del Ipeco, los puntos de corte (53.0, 59.9, 66.9, y 73.3.) se ven de la siguiente manera en el histograma:
Así se ven los puntos de corte en el gráfico de serie de tiempo:
Por último, se presenta el código de Python necesario para generar la escala cualitativa:
def gen_escala(datos, variable):
'''
datos = DataFrame.
variable = texto con el nombre de la variable.
'''
c1, c2, c3, c4 = datos[variable].quantile([0.2, 0.4, 0.6, 0.8])
clasificacion = []
for e in datos[variable]:
if e < c1:
clasificacion.append('Muy pesimista')
elif e >= c1 and e < c2:
clasificacion.append('Pesimista')
elif e >= c2 and e < c3:
clasificacion.append('Neutral')
elif e >= c3 and e < c4:
clasificacion.append('Optimista')
else:
clasificacion.append('Muy optimista')
return pd.DataFrame(clasificacion, index=datos[variable].index, columns=['clasificacion'])
El resultado de aplicar el código anterior a la serie del IPECO se puede ver en la Jupyter Notebook relacionada.
Referencias
Bovi, M. (2009). Economic versus psychological forecasting. Evidence from consumer confidence surveys, Journal of Economic Psychology, Volume 30, Issue 4, Pages 563-574, https://doi.org/10.1016/j.joep.2009.04.001
Nota
El código utilizado en este artículo se puede descargar en GitHub. También puedes visualizarlo en Jupyter Notebook.